SHADHO: Massively Scalable Hardware-Aware Distributed Hyperparameter Optimizer
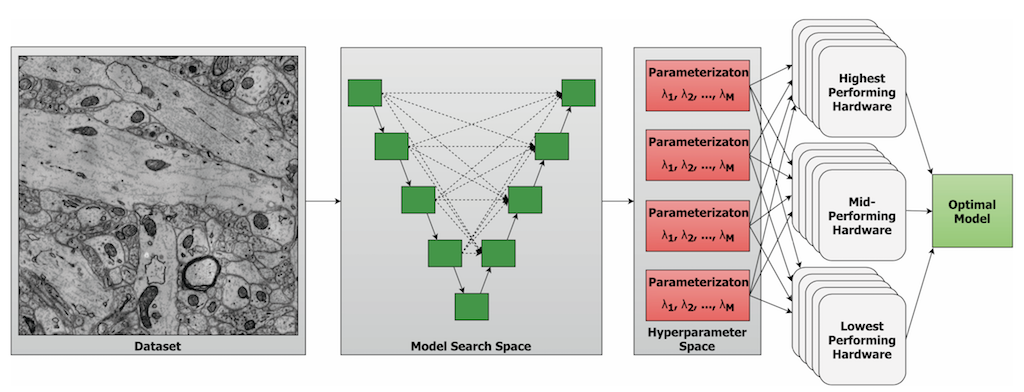
Hyperparameter optimization is a difficult but necessary part of training machine learning models. Differently-parameterized models must be fully-trained and evaluated independently, and performance cannot be known beforehand. The most efficient way to do this is to distribute candidate models to multiple workers which may have different hardware (e.g., more/fewer cores, different GPU models, etc.).
A number of frameworks exist to perform distributed hyperparameter optimization, but most assume that all models in the search are equal and all available hardware is equal. In doing so, potential systems-level optimizations are overlooked. Additionally, other frameworks tend to limit the number of available strategies for generating hyperparameters (e.g., Random Search, Tree-Structured Parzen Estimators, SMAC), forcing researchers to reinvent the wheel each time a new strategy is introduced.
The SHADHO framework is an open source software project that aims to enable machine learning with efficient distributed searches and modular search strategies. By sending models with larger search spaces and less certain performance to higher-performing hardware, SHADHO is able to increase the throughput of a search over competing methods that do no scheduling. SHADHO searches are not tied to any particular search strategy, and a number of strategies are available out of the box.
Jeffery Kinnison, Walter Scheirer
Collaborators: Nathaniel Kremer-Herman, Douglas Thain
SHADHO: Massively Scalable Hardware-Aware Distributed Hyperparameter Optimization, Jeff Kinnison, Nathaniel Kremer-Herman, Douglas Thain, Walter J. Scheirer, Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), March 2018: [pdf]