Projects
Current Projects
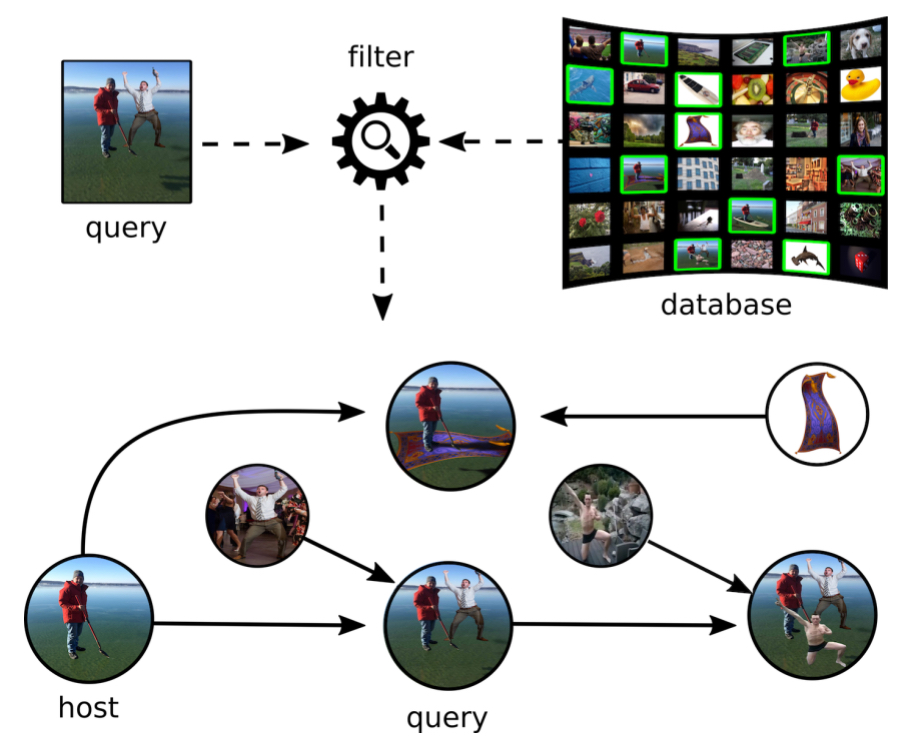
Ubiquity in the presence and usage of imaging technology has led to increase in concerns regarding the authenticity of circulated media. This project attempts at improving detection and analysis of questionable media objects. The ultimate goal is to discover the provenance of the object with respect to the content and time among millions of images.
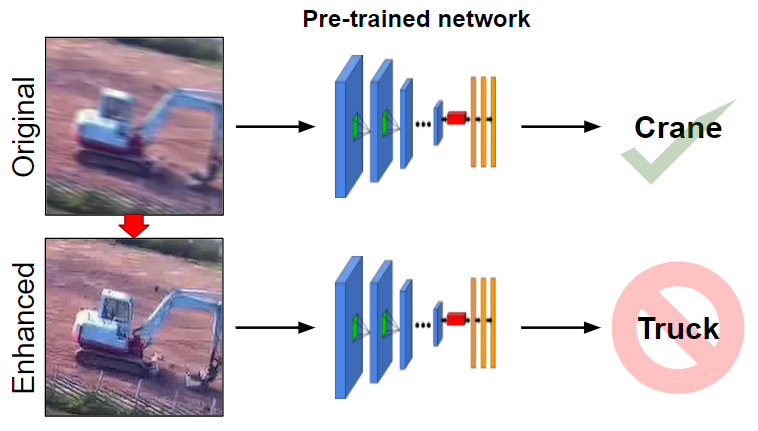
To build a visual recognition system for any applicationthese days, one's first inclination is to turn to the most recent machine learning breakthrough from the area of deep learning, which no doubt has been enabled by access to millions of training images from the Internet. But there are many circumstances where such an approach cannot be used as an off-the-shelf component to assemble the system we desire, because even the largest training dataset does not take into account all of the artifacts that can be experienced in the environment. As computer vision pushes further into real-world applications, what should a software system that can interpret images from sensors placed in any unrestrictedsetting actually look like?

The transcription of handwritten historical documents into machine-encoded text has always been a difficult and time-consuming task. Much work has been done to alleviate some of that burden via software packages aimed at making this task less tedious and more accessible to non-experts. An automated solution would allow for not only preservation of our cultural heritage but also opens the door to taking advantage of recent advances in artificial intelligence to automatically analyze these documents. Therefore, we have embarked on a project to automatically transcribe and analyze Medieval Latin manuscripts of literary and liturgical significance.
The ease with which one can edit and redistribute digital documents on the Internet is one of modernity's great achievements, but it also leads to some vexing problems. With growing academic interest in the study of the evolution of digital writing on the one hand, and the rise of disinformation on the other, the problem of identifying the relationship between texts with similar content is becoming more important.

COVE is an online repository for computer vision datasets and tools. It is intended to aid the computer vision research community and serve as a centralized reference for all datasets in the field. If you are a researcher with a dataset not currently in COVE, please help make this site as comprehensive a resource as possible for the community and add it to the database!

Digitally altering, or retouching, face images is a common practice for images on social media, photo sharing websites, and even identification cards when the standards are not strictly enforced. In this project, we aim to develop algorithms of detecting retouching effects in faces. We also analyze the covariates of the problem and improve the approach to attain generalizability across different types of demography. For the purposes of this research, we also developed the largest existing non-celebrity retouched dataset with retouched and un-retouched images.

The use of small Unmanned Aerial Vehicles to collect imagery in difficult or dangerous terrain offers clear advantages for time-critical tasks such as search-and-rescue missions, fire surveillance, and medical deliveries. Employing a drone to search for a missing kayaker on a river or a child lost in the wilderness, survey a traffic accident or a forest fire, or to track a suspect in a school shooting would not only reduce risk to first responders, but also allow for a wide-scale search to be deployed in an expedited manner.
Rosaura G. VidalMata, Sreya Banerjee, Sophia Abraham, and Walter J. Scheirer
When an autonomous vehicle makes a lethal mistake, one should question the degree of trust we place in such decision making systems. Machine learning systems such as this have largely risen from the wave of remarkable machine learning advancements made possible by the substantial increase in data and compute power. While these breakthroughs have led to a multitude of applications that positively impact lives, one should not forgo thorough assessment prior to conceding complete trust in them. In Visual Psychophysics for Machine Learning, we attempt to bridge the gap between Machine Learning theory and its application by using Visual Psychophysics, a technique developed and employed by vision scientists for over a century. By studying Machine Learning as a Psychologist would study biological vision, we can develop Machine Learning models that more closely mimic the robustness of its biological counterpart.
A flexible framework for sparsely segmenting and reconstructing neural volumes without requiring expensive ground truth and training.

Computer vision is experiencing an AI renaissance, in which machine learning models are expediting important breakthroughs in academic research and commercial applications. Our framework calculates the relative complexity of each search space and monitors performance on the learning task over all trials.

A multi-institution effort to enable intertext matching in the browser with an updated version of the open source Tesserae software.

Achieving a good measure of model generalization remains a challenge within machine learning. The goal of this project is to investigate alternative techniques for evaluating a machine learning model's expected generalization. This project is inspired by the observation that neural activation similarity corresponds to instance similarity. Theoretically, a machine learning model that mirrored this observation would indicate a consistent understanding of stimuli, which extrapolate to unseen stimuli or stimuli variations. This project utilizes representational dissimilarity matrices (RDMs), which represent a model as it's activation similarity between pairs of responses to stimuli. The project experiments with a multitude of techniques to construct and utilize RDMs in and across model training, validation, and testing.
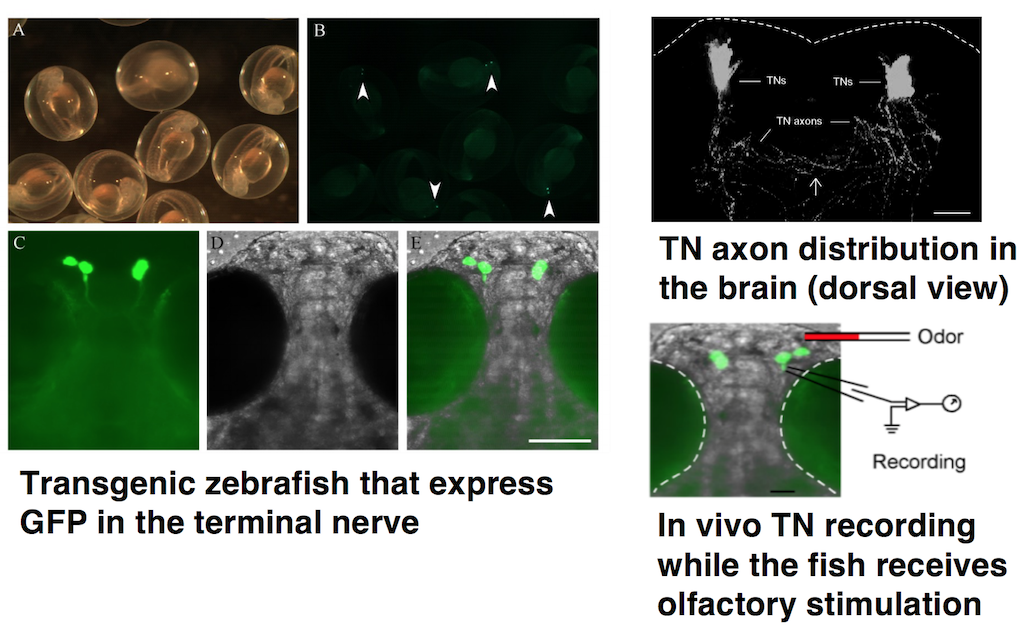
In this project, we investigate the cross-modal signaling interactions between different sensory systems, specifically the centrifugal signals in modulation of the visual system, in zebrafish. They originate in the Terminalis Neuron (TN) that is housed in the Olfactory Bulb (OB). Naturally, olfaction influences vision in zebrafish. Based on the results from wet-bench experiments examining the above circuit-level phenomena, we are working towards computational neural models that leverage the principles of the statistical extreme value theory (EVT) to simulate and predict the consequence of sensory integration in retinal function.
To tackle re-identify people within different operation surveillance cameras using the existing state-of-the art supervised approaches, we need massive amounts of annotated data for training. Training model with less human annotations is a tough task while of great significance, especially in deploying new recognition algorithms to a large-scale real-work surveillance camera networks. This project aims to develop reliable unsupervised method for handling the situation when large number of labeled data is not available in real world applications. We tried to combine unsupervised deep learning approach with new graph regularization to incrementally improve the recognition accuracy.
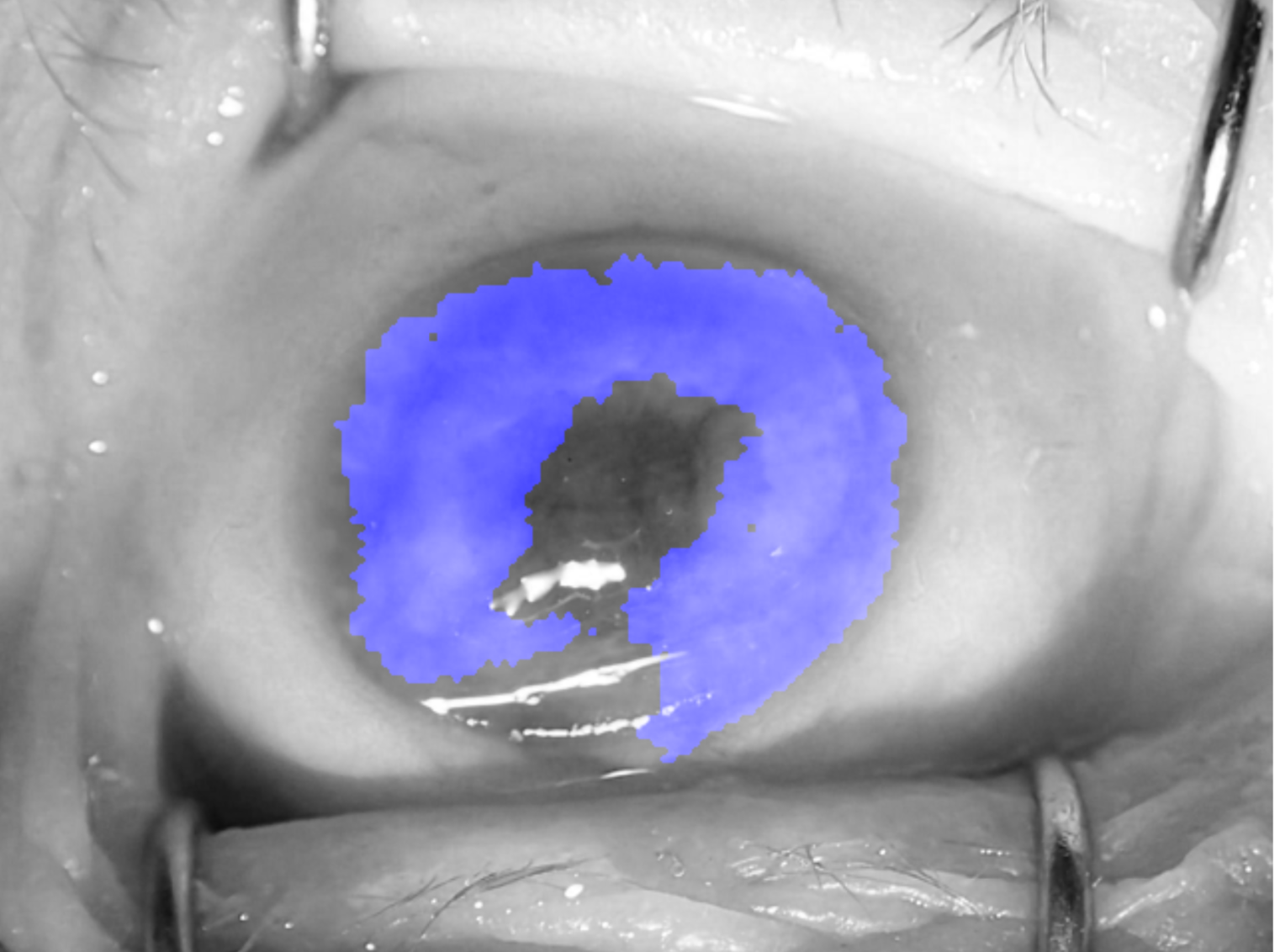
Iris image segmentation is the first and the most critical element of iris recognition pipeline. It is known to be difficult to be reliably executed by conventional iris recognition methods, especially for iris images not compliant with ISO/IEC 19794-6, such as pictures of eyes with conditions, or post-mortem iris samples. In this project we explore various deep-learning architectures to offer new methods in iris segmentation for challenging cases.
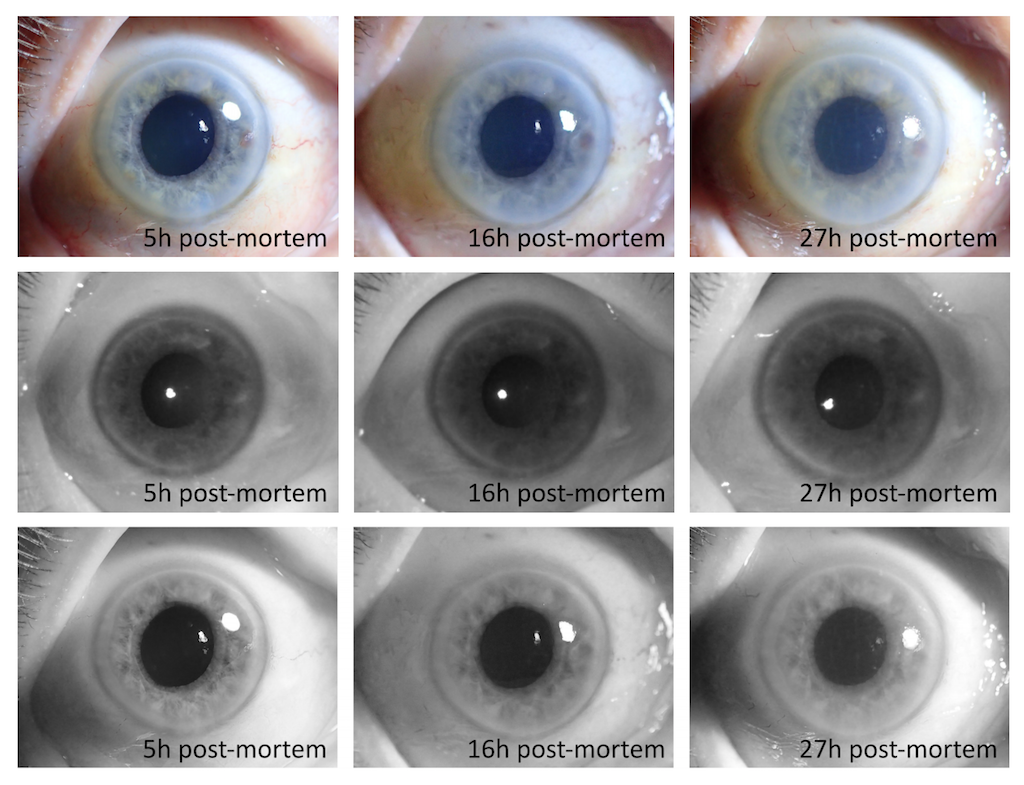
This project aims at delivering new iris recognition methods that can be applied to identify deceased subjects. In our past research we have demonstrated that post-mortem iris recognition can be viable until approximately 3 weeks after death if bodies are kept in the mortuary. Current research topics include (a) dynamics of deterioration in iris recognition performance and biological reasons of that deterioration, (b) development of new computer vision methods for processing of post-mortem iris images, (c) development of human-interpretable features that support human examiners in post-mortem iris image matching.
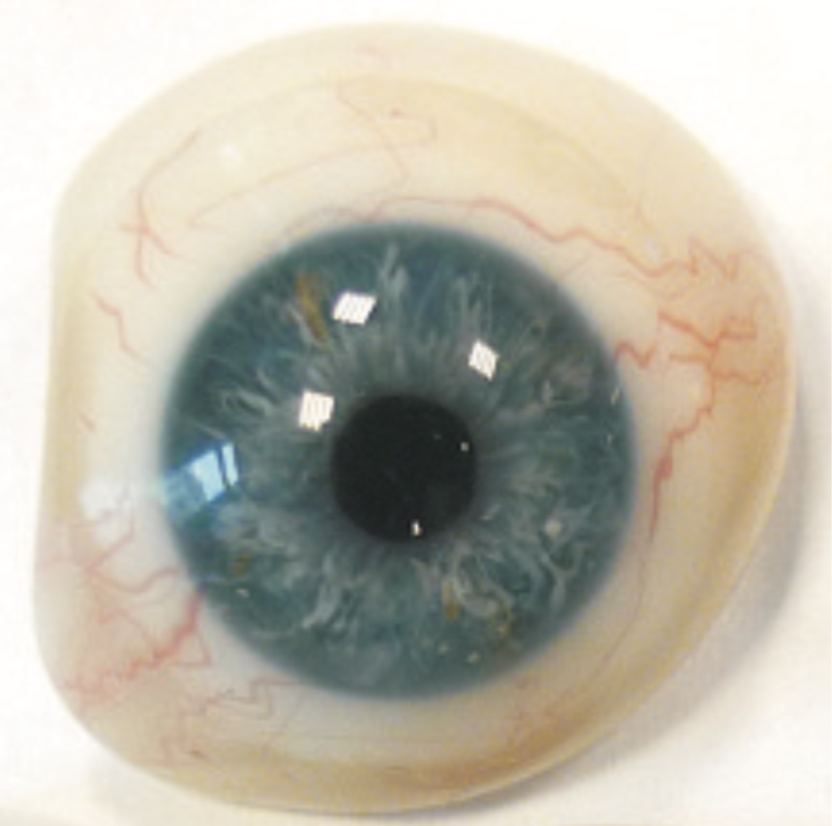
The term “presentation attack” refers to making a presentation to the sensor with the goal of manipulating the system into an incorrect decision. In this project we develop methods to detect diverse presentation attacks, including unknown presentation attack instruments. Our methods can detect diverse artifacts, such as textured contact lenses, iris printed on a paper, and even cadaver eyes, We are a co-organizer of the iris presentation attack detection competition LivDet-Iris (www.livdet.org), which had already three editions. Czajka and Bowyer prepared recently the most comprehensive survey on iris presentation attack detection (to appear in ACM Computing Surveys).
The goal of this project is to establish the use of accurate benchmarks of machine learning models on real-world data. Machine learning models are often trained and tested on simplified representations of data that cannot be replicated in the real-world. Reported results thus inflate machine learning performance, while obfuscating expected performance "in the wild".
Past Projects
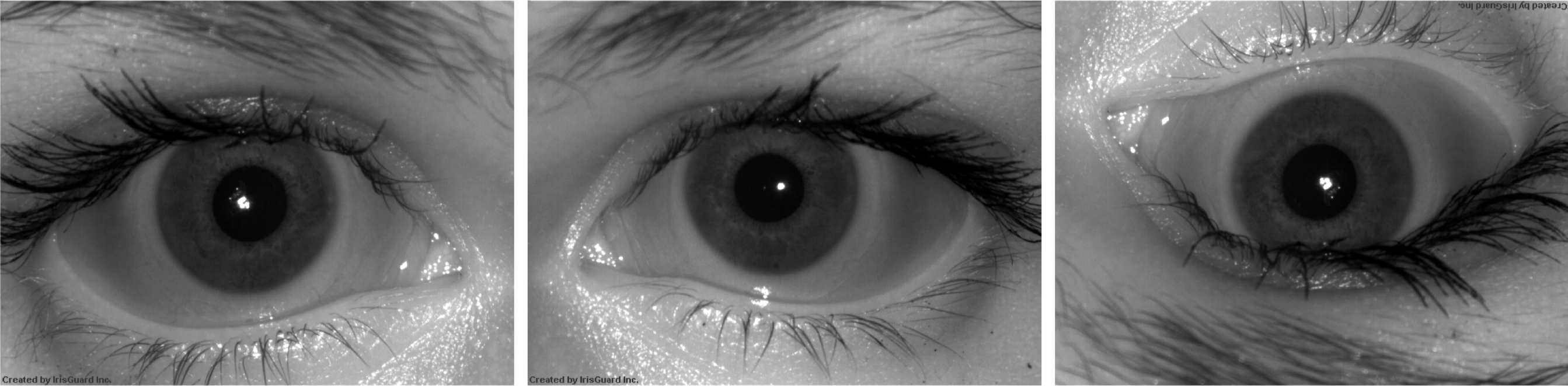
The purpose of the ACII Project was to develop algorithms and software tool to label the orientation of an iris image. The input is an iris image acquired using commercial iris recognition sensors. The output is a labeling of the left-right orientation and the up-down orientation of the image. The methods include both hand-crafted features and SVM classification, as well as deep-learning-based solutions. The accuracy of the labeling was estimated using existing iris image datasets previously acquired at the University of Notre Dame. The SVM-based approach achieved an average correct classification rate above 95% (89%) for recognition of left-right (up-down) orientation when tested on subject-disjoint data and camera-disjoint data, and 99% (97%) if the images were acquired by the same sensor. The deep-learning -based approach performed better for same-sensor experiments and presented slightly worse generalization capabilities to unknown sensors when compared with the SVM.

Face recognition performance has improved remarkably in the last decade. Much of this success can be attributed to the development of deep learning techniques such as convolutional neural networks (CNNs). While CNNs have pushed the state-of-the-art forward, their training process requires a large amount of clean and correctly labelled training data. If a CNN is intended to tolerate facial pose, then we face an important question: should this training data be diverse in its pose distribution, or should face images be normalized to a single pose in a pre-processing step? To address this question, we evaluate a number of facial landmarking algorithms and a popular frontalization method to understand their effect on facial recognition performance.
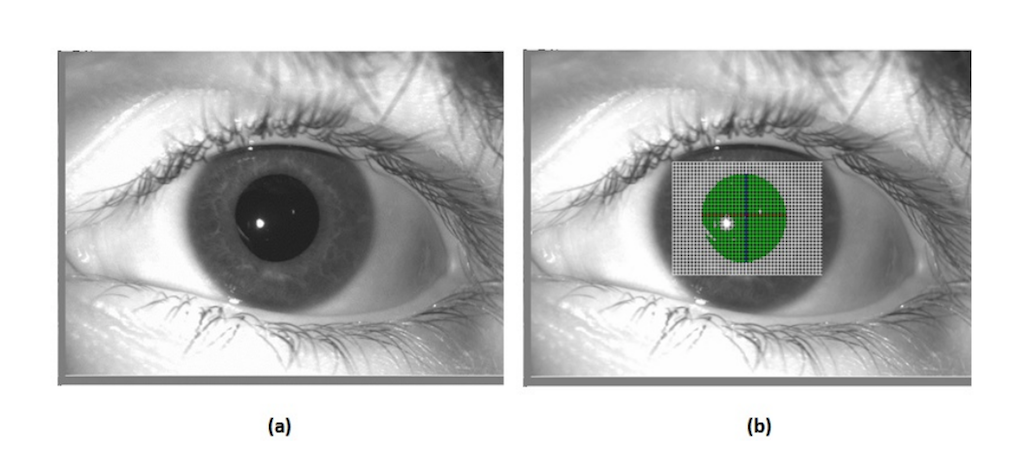
Iris segmentation is an important step in iris recognition as inaccurate segmentation often leads to faulty recognition. We propose an unsupervised, intensity based iris segmentation algorithm in this paper. The algorithm is fully automatic and can work for varied levels of occlusion, illumination and different shapes of the iris. A near central point inside the pupil is first detected using intensity based profiling of the eye image. Using that point as the center, we estimate the outer contour of the iris and the contour of the pupil using geodesic active contours, an iterative energy minimization algorithm based on the gradient of intensities.
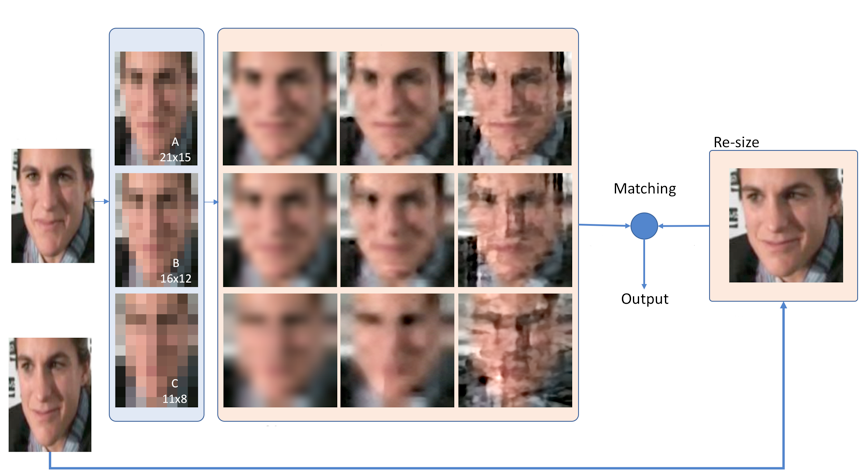
Although face recognition systems have achieved impressive performance in recent years, the low-resolution face recognition (LRFR) task remains challenging, especially when the LR faces are captured under non-ideal conditions, as is common in surveillance-based applications. Faces captured in such conditions are often contaminated by blur, nonuniform lighting, and nonfrontal face pose. In this project, we are aiming at analyzing face recognition techniques using data captured under low-quality conditions in the wild. The performance gap between general unconstrained face recognition and face recognition in surveillance videos is shown and new algorithms are designed to tackle this specific problem.

This project addresses the inward-facing and important problem of athlete skill level characterization and tracking. The goal of the project is to measure performance-critical quantities unobtrusively, rapidly, and frequently. The team pursues this goal through the design and deployment of an measurement platform incorporating force plate sensors (that measure the 3D distribution of force produced by a stationary, moving, or jumping athlete) and skeletal tracking based on markerless video analysis.

We propose a novel face synthesis approach that can generate an arbitrarily large number of synthetic images of both real and synthetic identities with different facial yaw, shape and resolution.
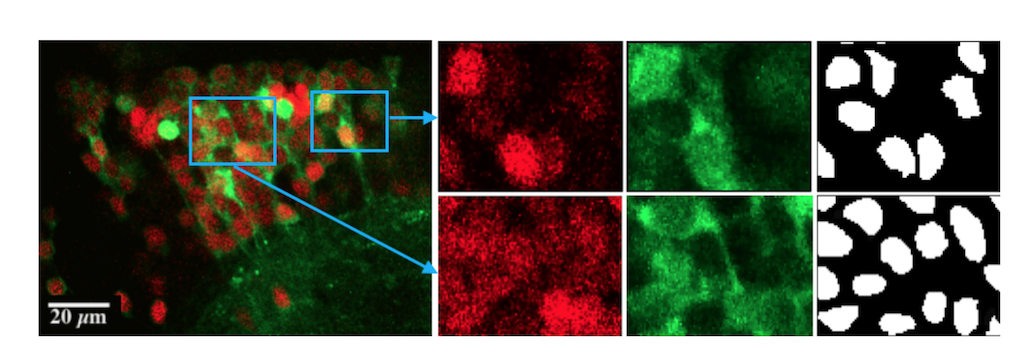
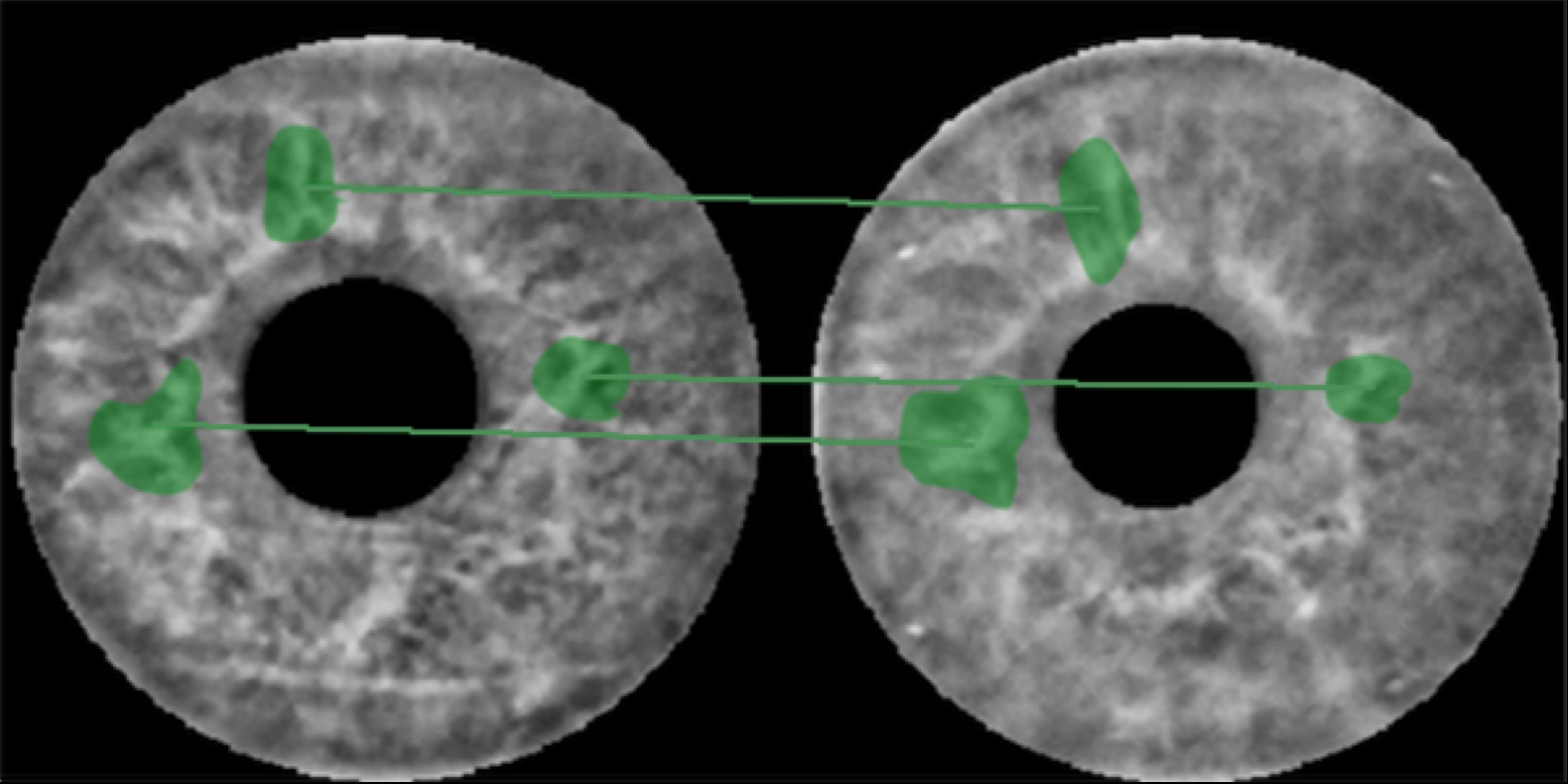
In this project, we consider the problem of automatically segmenting neuronal cells in dual-color confocal microscopy images. This problem is a key task in various quantitative analysis applications in neuroscience, such as tracing cell genesis in Danio rerio (zebrafish) brains. Deep learning, especially using fully convolutional networks (FCN), has profoundly changed segmentation research in biomedical imaging.
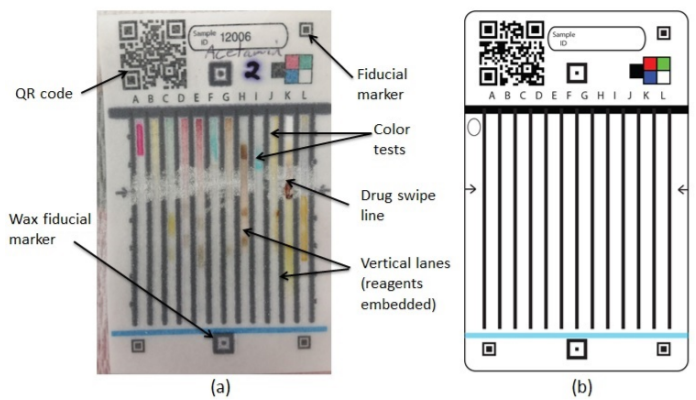
Falsification of medicines is a big problem in many developing countries, where technological infrastructure is inadequate to detect these harmful products. We have developed a set of inexpensive paper cards, called Paper Analytical Devices (PADs), which can efficiently classify drugs based on their chemical composition, as a potential solution to the problem. These cards have different reagents embedded in them which produce a set of distinctive color descriptors upon reacting with the chemical compounds that constitute pharmaceutical dosage forms.

Person re-identification (ReID) is a popular topic of research. Almost all existing ReID approaches employ local and global body features (e.g., clothing color and pattern, body symmetry, etc.). These `body ReID' methods implicitly assume that facial resolution is too low to aid in the ReID process. This project attempts to explore and show that faces, even when captured in low resolution environments, may contain unique and stable features for ReID. We contribute a new facial ReID dataset that was collected from a real surveillance network in a municipal rapid transit system. It is a challenging ReID dataset, as it includes intentional changes in persons' appearances over time. We conduct multiple experiments on this dataset, exploiting deep neural networks combined with metric learning in an end-to-end fashion.